Landing a message from Kafka
As I’ve been working more with Kafka, I’ve realized that a large amount of the pain is related to the deserialization of data. So increasing our understanding of this piece of Kafka programming is a good use of time.
In this article we’re going to explore a single question—how does an Avro-formatted message go from being stored in a topic to a strongly typed object in a consumer application?
You’ve got a new message
Our consumer application polls the Kafka cluster to see if there’s any new messages. Once there is, the binary data of the message is delivered over TCP to the consumer application.
The message has a schema id as the first 4 bytes (that would be an Int) of the message’s payload. The KafkaAvroDeserializer gets that id, and goes to the schema registry to get the corresponding schema.
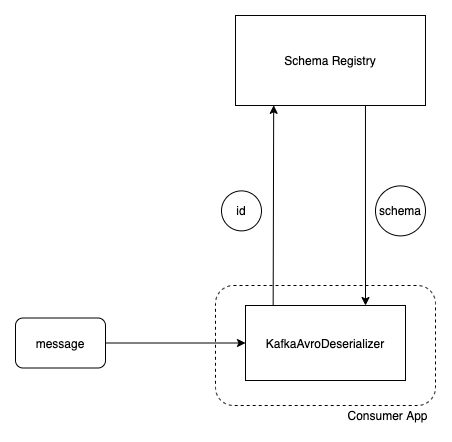
Through that id, we now have the writer’s schema.
{
"type": "record",
"name": "Cup",
"fields": [
{
"name": "a",
"type": "long"
},
{
"name": "b",
"type": "string"
}
]
}
You must have the writer’s schema
An interesting fact about Avro is that in order to deserialize data, you must have the writer’s schema at read-time. This is because in Avro’s binary format, the message doesn’t contain field names or separators. e.g.
{
"type": "record",
"name": "Cup",
"fields": [
{
"name": "a",
"type": "long"
},
{
"name": "b",
"type": "string"
}
]
}
Cup(a=27, b="foo")
36 06 66 6f 6f
// in non-hex:
27 3 f o o
Notice how there’s no field names or separators. That’s part of what makes Avro fast and compact—but it also makes it impossible to read the message without the schema it was produced with. So remember:
Avro requires the writer’s schema at deserialization time.
Back to landing the message
Once the KafkaAvroDeserializer has the writer’s schema and the binary data of the message, how does it deserialize it?
At this point, things differ depending on how we’ve configured our application. We have a choice of deserialization target—do we want the message to end up as a Java object generated from an Avro schema file (the SpecificRecord approach), or into a GenericRecord (essentially an untyped map).
GenericRecord Approach
At this step, Avro’s DatumReader recursively (depth-first!) works through the binary data that represents the message, using the format of the schema.
When it gets to a leaf node, it reads the data using the Avro type stated in the schema and converts it to an in-memory representation.
When you access the data from the GenericRecord, you’ll get an Object. The types in this case are only used for deserializing the data.
When we take this approach, it’s common to have one more deserialization step from GenericRecord to a POJO—but this is outside of the realm of Kafka and Avro.
SpecificRecord Approach
When we’ve specified SpecificRecord as the deserialization target, we create a DatumReader with two schemas—the writer’s schema and the reader’s schema.
This time when it reads the data it goes through Avro’s schema resolution to resolve the data to the final object—one that’s consistent with the reader’s schema, and strongly typed.
Avro Schema Resolution?
There’s a detailed section about this in the Avro specification. The gist of it is that the writer’s and reader’s schemas can only be different in allowable ways. Some examples would be:
- The writer’s schema contains a field not in the reader’s schema — that’s fine, it’s ignored.
- The reader’s schema contains a field not in the writer’s schema, and the reader’s schema specifies a default value — that’s fine, we’ll set the default value for that field.
An example of something not allowed would be the reader’s schema containing a field not in the writer’s schema, and with no default value. Then you’ll get a DeserializationException.
Let’s review our diagram so far.
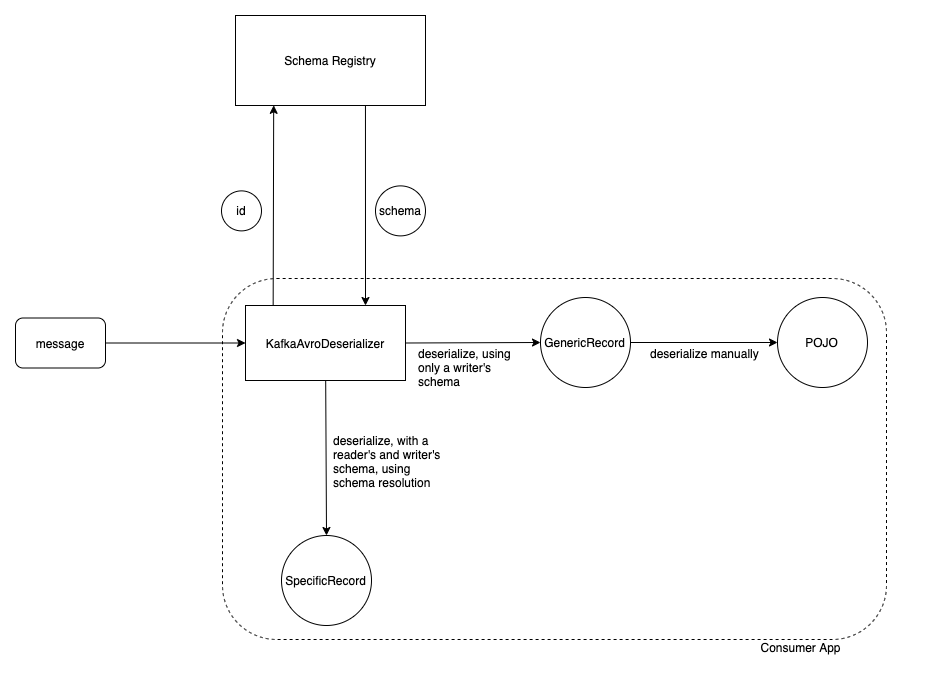
Which approach should I take—GenericRecord or SpecificRecord?
As we mentioned earlier, GenericRecord is like an untyped map. I like to think of JavaScript object. SpecificRecord is a class generated from a build task—using an Avro schema file stored with the repo.
The benefit of the SpecificRecord approach is that the landing target for the message is a strongly typed POJO right out of the gate. This doesn’t necessarily mean that it is generated from the writer’s schema, just one that is compatible with the writer’s schema. The nice part about this approach is you get Avro’s schema resolution to work for you.
For me personally, I strongly dislike the idea of using generated classes and of keeping schema files locally in a repo. I don’t think it’s too much work to have a second deserialization step from a GenericRecord to a POJO. Furthermore, this extra deserialization step can give you a chance to rectify any types you are uncomfortable with, in ways that Avro’s schema resolution couldn’t handle.
The con of this approach is that you have to make sure your implicit reader’s schema (contained in the POJO your deserializing to) is still compatible with the message. You can’t let the explicit writer’s schema (stored in the schema registry) and your business logic class diverge in incompatible ways. Schema evolution is a real challenge no matter what approach we take.
Touchdown
Once we’ve deserialized the message to an in-memory object, we’re done with one of the most painful parts of developing a Kafka consumer application. From here we can do any the cool things that Kafka gives us the power to do.